

What can be at the State Department, unburdened by what has been

Welcome to Memetic Warfare.
My name is Ari Ben Am, and I’m the founder of Telemetry Data Labs - a Telegram search engine and analytics platform available at Telemetryapp.io. I also provide training, consulting and research so if you have any specific needs - feel free to reach out on LinkedIn.
We’ll start off this week with some recommendations:
The first is LoL Archiver. LoL Archiver archives the username and bio history of Twitter users, and enables search by User ID.

User IDs are still comparatively less-commonly used on Twitter, and it’s great to see a tool emphasize their importance for tracking unique accounts over time.
The second tool is Flinfo, née “What China Reads” (which is how I first came across them). Flinfo makes news sources in Chinese, Russian, Arabic, French and even Vietnamese apparently available in a convenient feed, including translation
Below, see a screenshot of what Chinese news sources are saying on the Philippines - you can filter by region, topics and so on.
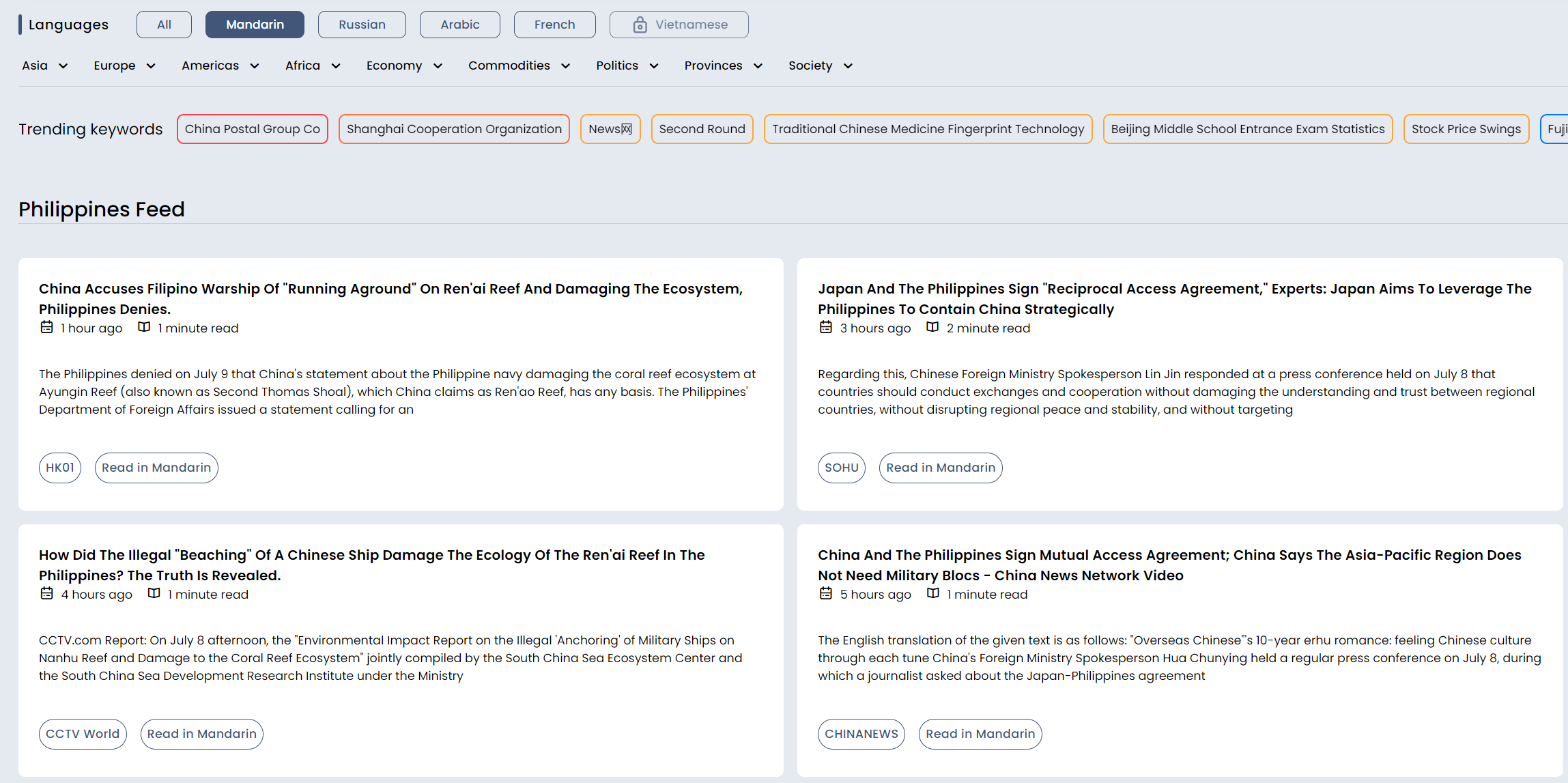
Flinfo is a great tool, and I have no commercial relationship with them - I’m just happy to promote journalism and OSINT startups providing affordable and powerful tooling. Check it out today if you’re interested in monitoring the global media landscape!
On that note, let’s begin with a look at breached data.
Recorded Future new research on using infostealers logs to “unmask” CSAM consumers is a fascinating report and shows how breached data can be critical for cracking previously impossible types of investigations.
Despite becoming more commonly known in recent years, infostealers are still lesser-known in the world of breached data. Infostealer logs are sold online by cybercriminals for exploitation by other criminals, and are often sold in batches of thousands or more of logs.
Check out the below image from Flare.io showing a channel for the notorious Redline stealer:

I’ll give Hudson Rock a shoutout for being among the first to recognize the OSINT/CTI value of infostealers, and you should check out their tool for protecting yourself from infostealers here. They also run a fantastic blog on at infostealers.com.
In contrast to typical breached databases, in which a given victim appears as but one row in a larger databse with limited information, infostealers are malware that infect a given device, and can pull data from it comprehensively. That data can include:
Applications
Device information
Keylogging
Passwords/cookies/more
Crypto wallet credentials
Other information as needed
Check out a below file sample from Flare.io showing an infostealer log for a given device:

If you’re interested in doing research on infostealers for CTI purposes, check out Telemetryapp.io - we have hundreds of thousands of results in total mentioning specific stealers (see the two below):

So, infostealers can extract tons of data on a given victim, including credentials, cookies and more. It should come as no surprise then that many breaches then occur due to a given user at a company or organization having been pwned by an infostealer.
Recorded Future took that mindset and applied it to investigations in their report.

We can see the immense value of infostealer logs by looking at one example of a given user:
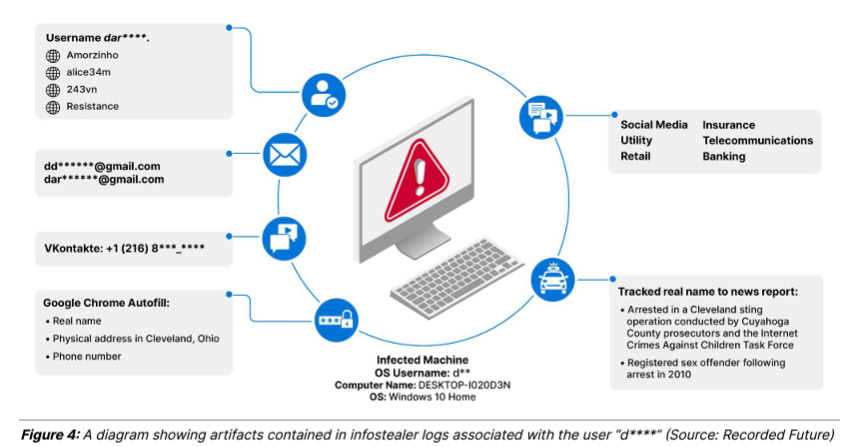
So we can see here that Recorded Future was able to get a core list of domains together, query them across infostealer logs and find users allegedly involved in CSAM from there.
Let’s think about this for a moment. Could we apply the same dynamic for investigation of influence or cyber operations? The answer is yes, and it’s already beginning to be done by some. Imagine getting an infostealer log from an i-Soon employee or member of the Russian military or so on.
We’re still getting around to the use of breached data for investigating and attributing threat actors online, but infostealers have still been neglected compared to regular breaches.
There are reasons for this. Infostealers contain much more sensitive data when compared to regular data breaches, and making an aggregation tool for that available commercially could be problematic ethically if not legally. Additionally, infostealers are still growing in total usage online, and the corpus of online data available from breaches is still much larger than that from infostealers.
Having said that, companies are finally getting into the space and it’s a matter of time until infostealer data is integrated into the currently-available breached data investigation tools.
Let’s keep the good times rolling with another banger from Recorded Future, available here. When it comes to sharing content on this blog, I aspire to only post bangers, and RF has frankly been bringing the heat as of late.

I’ll share the key findings below with one of my few formatting notes: make my life easier and have these be on one convenient page please!

So why am I so effusive about a report that covers previously-exposed networks? Well, the first reason is that looking at hte same operation over time is still not done commonly enough (Spamouflage and Doppelganger excepted), and the operational tempo here is impressive.
What I want to point out in particular are OpSec breaches caused by the LLMs that the operation utilized:

Apparently, leaving prompts in articles has happened more than once, and even includes some translated into French. See an example from one of the domains below:
The next tip of the proverbial fedora comes due to the coverage of Iranian IO. Iran is still not covered enough and it’s great to see more network recidivism (here from IUVM) brought up:

What can be at the State Department, unburdened by what has been
The State Department has been making much ado about their adoption of AI, releasing a two-hour long YouTube video of a recent conversion held with Blinken and other American officials, available here.
I won’t torture you so we’ll skip straight to the relevant part of the transcript, available here and below. The main point relevant for this humble blog is the mention of “Northstar”, an AI data analytics platform for news articles.
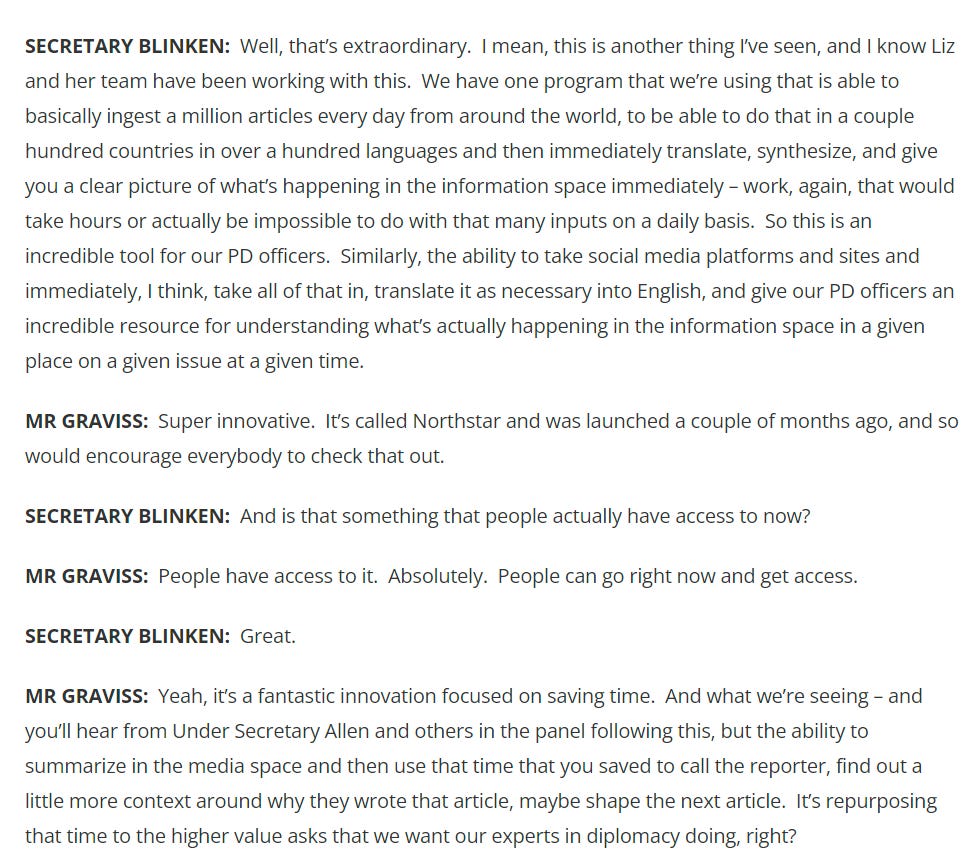
So essentially the State Department has developed internally a news data platform? Has the State Department begun to dip its toes in bespoke software development?
Blinken also mentioned social media, which I’ll get to later.
Not bad I guess, but there are plenty of other commercially available solutions that probably would have been cheaper to use and integrate with Open AI, Claude or what have you.
To be honest, I doubt that the State Department actually developed this platform. They probably white-labelled an extant news API or other data platform and integrated it themselves with ChatGPT. I certainly hope that that’s the case at least, as that would be the best and most efficient use of taxpayer dollars.
News data is comparatively easy to work with as well, as it’s just regular web scraping.
The next step, scraping social media at the same scale, is nigh impossible, and that’s where most of the real value is arguably to be found. Blinken referred off-hand to social media collection here, but collection and analysis of social media at scale is a huge issue and one that isn’t discussed as much as it should be.
You can access data at a large scale and for a hefty fee via the Twitter API, as well as via the YouTube API (to a certain limit), and a few others such as Reddit. Want anything from Telegram? Check out Telemetryapp.io, so that one’s easy.
Want anything from Facebook, WhatsApp, Instagram, TikTok or myriad other platforms? You have to fulfill very specific criteria to receive it from the platforms themselves, which the US government often doesn’t fulfill. Alternatively, you can pay for scaled access from companies like Bright Data, but this adds up significantly over time to say the least.
Need anything from Chinese social media platforms, other messaging applications or other regional social media platforms? Best of luck to you carrying out scraping at such a large scale.
Why do I bring this up?
Because it’s important to remember that the bottleneck for much of the IO space still isn’t just sheer analytics/compute power via LLMs, but rather legal and ethical access to data at scale. Domain data can be scraped comparatively easily, but most platforms are exponentially more difficult to access while being critical to actually identifying and investigating IO.
The US government has the ability to pay for access to this sort of data at scale, but acquiring it legally and ethically is still a challenge.
In fact, according to insideaipolicy.com, Northstar’s social media capabilities are limited to “evaluating the efficiency of Department-owned social media and understanding communications from foreign-government owned social media”.

This is a much, much more limited and realistic scope. Perhaps most notably this is a capability that already exists via commercial “social listening” applications.
Overall, I’d classify this as a win. Worst-case scenario, the State Department spent too much money developing a news data platform and is proactively thinking about LLM use. Best-case scenario, they cost-efficiently white-labelled an extant platform and are using it as well. Hopefully the next step is some sort of thinking about how to exploit public data on social media and other platforms beyond news data.
I’m also a fan of their proactive discussion of AI. No one may truly care about what they upload to YouTube or post publicly, but I personally appreciate the transparency and building-in-public mindset here, and believe that it will be fruitful going forward.
Let’s conclude with the GMFUS’ study into the Russian “information laundering” industry, available here. Check out the key findings below.

Nice to see someone look at it, but includes main points that we’d expect to see:
RT and other Russian state media exploit third party websites and utilize mirror sites
User-generated content is big
Other state-media outlets utilize RT content, including those affiliated with Iran/Hezbollah
The ongoing war Israel-Hamas war is a big topic
So far, nothing that shocks me, but nice to see it covered regardless. That’s just one part of the press release though.
If you’re interested in carrying out similar research, the GMF has released their “Information Laundromat” tool, available here. The tool has a few capabilities, so play around with it.
Testing it out on Global Research to find unique indicators retrieves interesting results. In this case, I queried two domains (rt(.)com and swentr(.)site, an RT mirror site.
The UI has some work to be done, as it shows the results in a still somewhat unclear manner for shared infra.

Breaking these into two columns would go a long way.
There are some great things here, such as the use of tracking tags, and even CSS-class and other comparisons for general mapping. However, the inclusion of IP address as a tier-1 indicator is off as IPs are more often than not shared or commercial infrastructure. There are still other indicators that are missing, but the idea is great.
Having tested this tool out, it’s a nice place to start but still has issues. Bugs abound, which is to be expected but still highly problematic as many of them kill the utility of the UI. I’m sure that as this is developed we’ll see more utility come out of it, and it’s always a pleasure to see more specialized tooling be released.
That’s it for this week. If you’ve made it this far, check out Telemetryapp.io and check out next week’s post!