

MWW 6: Botz II Networks
Midjourney Memery, Shark Guns and More

Welcome to Memetic Warfare Weekly’s third post!
I’m happy to have you here. My name is Ari Ben Am, and I’m the founder of Glowstick Intelligence Enablement. Memetic Warfare Weekly is where I share my opinions on the influence/CTI industry, as well as share the occasional contrarian opinion or practical investigation tip.
I also provide consulting, training, integration and research services, so if relevant - feel free to reach out via LinkedIn or ari@glowstickintel.com.
Thanks for reading Memetic Warfare (bi)Weekly!
This week’s post will focus on two main sections:
A beginner’s investigation guide for IO
Industry updates, news and developments
Let’s start with the beginner investigation guide:
Botz II Networks
One of the questions I’m asked most often is how to actually begin investigating IO. As such, I figured that it’s a good time to show how low the barrier to entry can be for investigating IO at a basic level by carrying out an investigation on Twitter, the easiest platform to investigate. Disclaimer: only investigate if you have a (reasonably) secure and anonymous framework and infrastructure to do so. Do not try to replicate this without practicing OpSec!
One of the tenets that underpins my approach to IO investigation is what I call “entity-based source development”. Many investigations are reliant on keyword input or other methods of flagging suspicious content.
This approach is inherently limited as it’s reactive - we have to essentially assume which keywords, hashtags and other input are relevant for identifying networks and then work from there. In the best-case scenarios we have to spend time reading state media narratives to further refine our searches. Most importantly, this approach is susceptible to the streetlight effect - we only see what we look for - see below for more discussion on that.
There are ways to mitigate the streetlight effect. The first key foundational element here is to understand that there is no one magic bullet for source development, and as such to implement as many different methods as possible for proactive source development. This includes, but is not limited to:
Keyword input on social listening tools (Tweetdeck, Awario and others).
Crowdtangling suspicious domains, accounts and more.
Monitoring state media and ad libraries.
Many, many more.
The second is to work smart, not hard: have the internet do as much of the work for you as possible. The goal here is to identify entities that consistently post disinformation content that we can then use to pivot to identify networks by looking for cross-posting, shared characteristics and more. We can use these entities to identify keywords, unique identifiers, images and more that can be searched across platforms to easily identify networks across the internet. The more specific, indicative and cross-vector (text, images, video, hashtags) - the better. This also is beneficial in that we catch disinformation at an earlier stage of dissemination than we do by searching for specific keywords.
How do we do find these magic entities that produce content upon which we may pivot? There are two main ways:
Crowdsourcing data - for example, follow online entities that discuss IO/disinformation and identify relevant entities to follow from their reporting:
reddit.com/r/activemeasures.
Journalists/Specialists.
We’ve looked at a few in the past, such as All Eyes on Wagner and others.
Think tanks.
Others.
Algorithm Exploitation - most platforms have recommendation features:
“you may also like”
“recommended”
“users also follow”
These provide users with a constant stream of content to doomscroll. We can utilize this to provide us with a steady stream of entities once we identify a small number of entities to begin with.
These two tenets are the foundation of entity-based source development, which is, in my humble opinion, the most effective and also entertaining way to stay abreast of developments in the field and identify networks.
Let’s take this method for a spin.
Just as an aside: the purpose of the below exercise is not to be a full, comprehensive investigation from A to Z, but rather aspires to show people how to get their feet wet in the field (only as they practice responsible OpSec of course) and to point out a few key indicators and methods that we can use to investigate IO.
One of the easiest ways to begin with entity-based source development is exploiting state media and diplomatic corps accounts on Twitter. We can easily identify, for example, Chinese state media figures or diplomats online, follow them, and then receive, courtesy of Twitter, recommended accounts to follow.
Recommended accounts aren’t the only vector here to utilize. Accounts that the target account retweets or engages with, content posted by the target account and more are all vectors that can be easily utilized to find other relevant sources of disinformation straight from the horse’s mouth.
Interestingly, I’ve noted that this works better and more consistently, with a higher number of recommended accounts, when utilizing the Twitter application (on an anonymous device and securely only, of course). There’s an element of luck with this, but the application I’ve found to be better consistently compared to the web app. One can also utilize this to build out a burner Twitter account with hundreds to thousands of entities quite easily with the “Follow All” button.
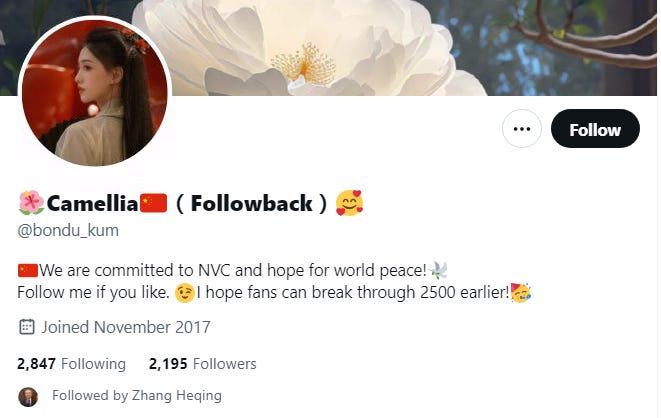
Look at the below results for following Zhang HeQing, a prominent Chinese diplomat.


Most but not all of the above accounts are suspicious. We could utilize this approach of course on any given Russian, Iranian, Venezuelan, Cuban, Belarussian (or other) public figure and retrieve suspicious bot accounts easily.
I utilized this approach recently on Zhang and got the account “🌺Camellia🇨🇳(Followback)🥰”.
Camellia tweets almost exclusively in English and on American and Western affairs:

Some of the images posted by Camellia are frankly, hysterical:

Gun violence appears to be a central theme of her recent posts, but I’m both happy that she chose to go with such a metal picture for the post while missing the obvious “The Room” reference which clearly would resonate with many more Americans.

Looking at the retweets of that tweet bring up a number of other inauthentic accounts that we could check individually for similar, cross-posted content.
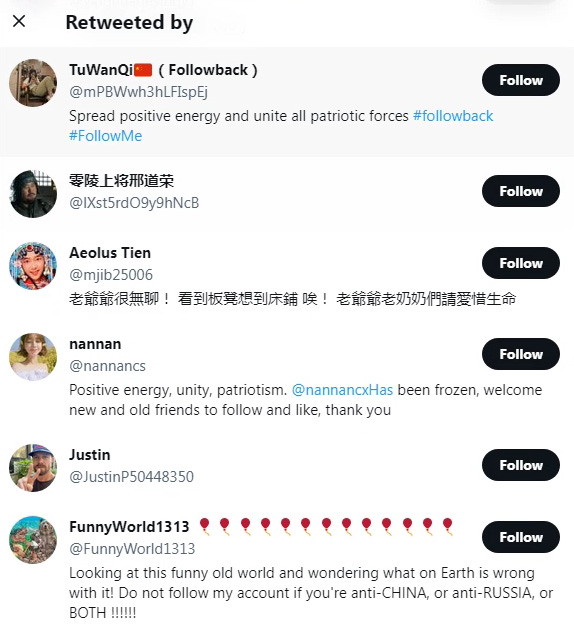
Looking at retweets and other Twitter activity, and maybe utilizing the API is where many investigations on Twitter would stop, but let’s take a look at Facebook and other platforms as well. The picture and text accompanying is what I call “indicative content”, meaning that it’s:
Disinformation/Propaganda Content.
Unique and easy to search.
The presence of this image and text together on a given entity would be indicative of its activity in the context of a wider network.
We could reverse image search the image in the above tweet, or alternatively search the text (or both). Insomuch as a quick reverse image search in Yandex wasn’t so effective, let’s search the above exact statement.

We get some Twitter results and most importantly, direct matches on a Chinese-language Facebook group and page. Let’s take a look at the first group:
中华民族的伟大复兴 - The Great Rejuvenation of the Chinese People/Nation (depends on how you choose to define 民族).

One of the first things to look at in any Facebook group is the “people” tab. I’m excluding any accounts from the screenshots that may be of real people, but of the 12 admins and moderators, at least half appear to be inauthentic. I’ll save you the screenshots of empty accounts with marching Chinese soldiers, tigers and other cliches.

We could then pivot easily upon these individuals by investigating their accounts, and also checking their posts in and out of this given group on Facebook. When doing so, be sure to search via Facebook’s internal search (while utilizing their user ID in the “posts from” section) as well as dork Facebook with their name for maximal coverage.
This group would also be a great entity to follow as part of your entity-based source development efforts.
Back to the topic at hand: we can see by searching “gun violence is tearing America apart” in the group that the exact post content has been shared in the group:

We can then pivot to the “Lovekh” page. This page has telltale signs of inauthenticity, content aside:
Created comparatively recently - April 2022.
Admins in locations that don’t match its activity: “unavailable”, Bangladesh, and the UK.
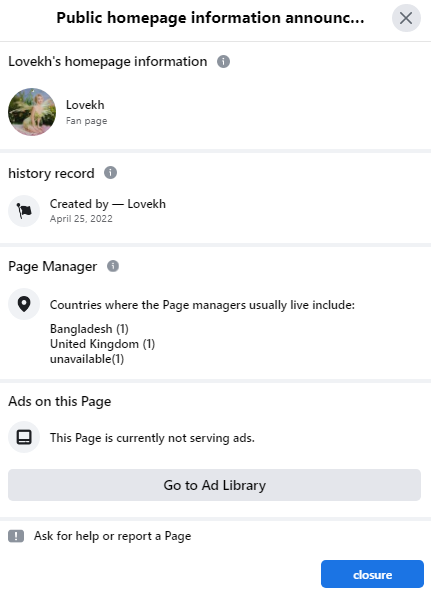
The page also of course posts almost exclusively anti-American content with very little engagement on average, despite having over 1,700 followers:


Our Sharknado-esque image, however, has over 1,300 likes and 30 shares - a huge spike compared to general activity:

We could then pivot to all of the shares of this post and begin to identify overlapping accounts, entities and other signs of coordinated activity.
This is an activity that we could easily continue ad-nauseum. For example, let’s go back to the Facebook page that we retrieved from the Google search:

This Facebook page shared the Sharknado-inspired image, but also promotes content from other pages, such as “Danika”. Looking at shares of this content can also be indicative of networked activity, as shown below by one “Amy Alexander”.

I’m OK with sharing this account insomuch as it is obviously inauthentic: Alexander has only one friend (based in Pakistan), and has no uploaded content short of spamming content from the above page, and potentially others, in various Facebook groups.

So, following a comparatively minimal investment of time and tools we’ve uncovered suspicious, cross-platform networked activity - in this case, suspected Chinese activity targeting American audiences.
While certainly at a very early stage and definitely too early to present or make sweeping conclusions, this activity can serve as a springboard for us to uncover larger, cross-platform networked activity and carry out a deeper investigation. Industry and academic researchers, I implore you: please look beyond Twitter! There’s a lot of low-hanging fruit out there that one can easily access with basic skills.
Some further investigation directions we could take:
Focus on Twitter, Facebook or other platforms. We could identify as many accounts/entitites as possible, look for stronger signs of coordination, carry out content and narrative analysis and present the findings as a network.
Look on other platforms for other activity - Reddit, YouTube and others - and further flesh out this activity and hope for adversarial OpSec errors.
Strive to identify domains that we could investigate via domain analysis techniques.
The above technique is only one of several effective ways to identify disinformation networks cross-platform while also staying up-to-date on new narratives and content - to hear more about those, feel free to reach out on LinkedIn or via glowstickintel.com
There is one thing that came up during this brief look at investigating networks that came up that I’d like to discuss: several accounts utilized AI-generated images, which appear to be Midjourney-generated.

The above image should be suspicious to anyone for several main reasons:
Trump has yet to be arrested and incarcerated, if at all.
Getting such a candid shot of Trump in jail would be functionally impossible.
Trump appears thinner than he often does.
There’s a distinct visual processing style unique to Midjourney that’s hard for me to describe, but once you look at say 10-15 images from it you’ll know what I mean.
The below image should be immediately suspicious to any viewer as it has one of the telltale signs of AI-generated images: fuzzy/nonsensical text. Look at the patch on the shoulder of the child in the image or the license plate of the car - the text generated isn’t written in any actual language.

Utilizing AI-detection tools such as the Hugging Face AI Image detector and the Hive Moderation AI Content Detector provides additional support to these images being AI-generated.


There’s been no lack of discussion of AI tools being used by Chinese, Russian and other networks. However, this is the first time that I’m aware of Chinese networks using AI-generated images for content generation and not just persona generation for inauthentic newscasts or GAN images for profile pictures.
If you are aware of other cases of Chinese networks (or any networks) utilizing tools such as Midjourney, DALL-E 2 or others, please reach out!
Now that we’ve gone over a (very) basic investigation, let’s look at some industry news and developments.
Dr. Wong, I presume?
In today’s important Chinese information operations news that, surprisingly, has very much flown under the radar of Western news outlets, a suspected Chinese espionage operation has been outed. The operation featured inauthentic Singaporean personas, alleged to be operated by China, targeting Indian journalists and soliciting articles from them on geopolitics.
The operation, reported on initially by the Hindustan Times, hits all of the tropes that we’re used to when it comes to overt Chinese combined espionage/information operations tactics:
Creation of fake academic personas
Contact via LinkedIn
This part was especially funny, as apparently the supposed researcher at a Singaporean think tank reached out to an Indian journalist with the following enticing offer: “So I wanna build a cooperation relation with you. Are you interested? Would you like to write something for me?”.
Hiring “guest writers” and experts to write on “hot events happening in the Asia-Pacific region” for approximately 400 USD an article.
Russia has also used the above tactic to solicit authors to write content for its own disinformation campaigns and websites, perhaps most notably with the now-exposed Peace Data operation. False personas (with the requisite GAN profile picture) were then used to promote these articles that were written by authentic people.

Source: CNN
This operation didn’t bother to try to spoof official think tank email addresses or even try to impersonate them with similar domains - some real low energy stuff. These initial invitations to write content are also common of Chinese espionage activity, and can be utilized for three main reasons:
Use as content for information operations/disinformation campaigns.
Utilize as part of routine intelligence-gathering.
Use as a hook to develop a relationship with the target, and eventually invite him or her to China.
This sort of activity is characteristic of Chinese malign activity in the region and internationally. The most famous occurrence of this was that of Dickson Yeo, a Singaporean PhD student who was recruited by Chinese agents over LinkedIn, invited to China for a conference and eventually indicted by the US for espionage activity targeting America.
¿Donde Esta La Biblioteca?
Google has decided to bless the community of open-source investigators and analysts with a public and searchable ad transparency center for Google products. Google's previous ad library only provided transparency for political ads in certain countries, while the new ad library will support commercial ads with a wider scope. To be honest, the previous political ad library wasn’t bad but was inherently limited, as many information operations don’t accurately label their ads as political for obvious reasons.


This is especially crucial, not just because it empowers the public, but because of the methods that platforms use to expose information operations.
Many information operations, especially those uncovered by platforms themselves, are exposed by the utilization of ad spend on platforms for amplification and promotion. This is the case for a variety of reasons, including more stringent KYC and AML regulation necessitating basic checks and friction for any payments rendered, as well as additional regulation for political ads. Providing this resource to the public will further empower analysts to identify and investigate online influence networks in addition to other illegal or malign activity online.
For those looking to investigate ads across-platforms in the context of IO, or any other activity, I’d recommend looking at BigSpy.
Tweet Long and Prosper
Note: If you’re interested in this topic, look at Clement Briens’ blog on the FSB contractor 0day Technologies available here. Briens posted this on April 1st, but reading it alongside the Vulkan files can be beneficial for one’s understanding of the wider ecosystem.
The Washington Post, in conjunction with other international media outlets, exposed a massive database of thousands of internal files from Vulkan, a private contracting firm. Vulkan provides services and software for the Russian military establishment, focusing on cyber capabilities and tools, including IO. Not only that, but they also have a self-referential sense of humor when it comes to sending out holiday invitations to employees:

Source: The Washington Post
We’ll focus on the IO aspects, of course, of this leak. But first - for those interested - the Washington Post published an article summarizing the main points of the leak, available here.
The first point that I’d like to bring up is the difficulty of OpSec.
The larger any organization or operation is, the higher the chances they will carry out an OpSec breach. A Vulkan employee sent a test email from a Gmail account used for phishing attempts to a Vulkan corporate email address, thus tying the two together. This email address was then used numerous times to send phishing emails to targets by Russian agencies. This is crucial to understand, as in many cases it is in fact far more feasible to attribute operations of any kind than many would normally think, if one knows how to do so effectively.
The second is the creation of the “Amezit” software solution, developed by Vulkan. Amezit automates the creation of social media accounts and entities at a large scale. Methods to bypass verification techniques on platforms are also integrated into Vulkan, such as the use of a SIM “bank” for account verification. The Washington Post has implicated Amezit as being used in a number of information operations both targeting the US (in particular, Hilary Clinton) and of course in and out of Russia in other operations.
Amezit also provides social listening and analytics features to its operators, with some hints that perhaps it enables them to more directly control network traffic. Additionally, Amezit may support other vectors of information dissemination, such as phone calls, emails and text messages beyond social media.
Cry “Discord” and Let Slip the Servers of War
Jordan Schneider, the creator of the excellent ChinaTalk podcast and Substack an ever-astute observer of all things memetic (and on a sidenote, arguably my biggest inspiration for starting Memetic Warfare Weekly) tweeted an absolute banger on March 30th.
Schneider pointed out that Ukrainian Command & Control (C&C) are using Discord to coordinate operations. Not only do they appear to be using Discord, but Google Meet is also noticeable in the upper-left hand screen. Even more hysterically, a different user pointed out that the Discord server appears to be boosted.


Leaving the lulz of this scenario aside, and certainly it is arguably overburdened with lulz, there are some lessons to take from this.
Firstly - better OpSec is key - hiding the nature of a given tool or system used, and even more importantly: hiding unique identifiers and usernames in screenshots.
While this may seem like a misstep or oversight on the part of the Ukrainian military, there is some logic to utilizing Discord and other commercial tools in operational environments.
This primarily appears to me to be the result of necessity, but the convenience and utility of Discord, as well as other commercial tools - be they digital or physical - in the defense of Ukraine have so far been successful. So long as proper risk assessments are carried out (understanding that Discord only has basic levels of encryption, for example) - the utility of Discord for less-sensitive communication may well make sense over cumbersome and expensive secure systems that often don’t work so well anyway.
Trojan Spreadsheets
Dave Troy, an investigative journalist studying disinformation, was courteous enough to publish a spreadsheet of “Russia-adjacent” disinformation sites and make it accessible to the public. He chose to present this data in a visualized graph format earlier in the thread, but I’ll forgive him for having provided actual value to the wider community with this spreadsheet.


This spreadsheet is a great place to start for those interesting in studying disinformation and IO. Domain lists can be leveraged in a number of ways - ranging from utilizing Crowdtangle, domain analysis, finding similar sites via Similarweb, narrative analysis and more - and I recommend that anyone interested in working in this field begin preparing their own databases.
Keep in mind, however, that the spreadsheet isn’t perfect. The automated nature of collection has led to a number of irrelevant domains being added. A few examples include protonmail.com and foxbaltimore.com. There are also many disinformation domains that are indirectly-related to Russia at best. Many of these focus on health, financial or other disinformation for financial gain and often lift content from Russian domains, but aren’t Russian themselves.
The (Fake Account) North, Strong and Free
Someone is finally giving Canada some attention when it comes to IO. A recent study, reported on by the Globe and Mail, studied Russian malign influence efforts targeting Canada. You won’t be surprised to hear that the narratives and content were functionally the same as other Russian activity, such as:
Targeting Ukrainians in Canada
Russia is “Denazifying” Ukraine
Canadian sanctions harm Canadians
Some trite, uninspired content to say the least. You also almost certainly won’t be surprised to read that this study of a number of Russian accounts focused on Twitter! I seriously wonder what academics will do once Twitter implements its new pricing model, pricing out anyone unwilling to either settle for the “Hobbyist” package or alternatively spend tens of thousands of USD monthly.
My personal hope is that this leads academia to begin to actually investigate off of Twitter and not reply solely on API access.

Source: https://first-the-trousers.com/hello-world/
The current state of research suffers from the “Streetlight” effect, in which most researchers only research where they have easy, direct access. It’s time for academia to incentivize BA, MA and PhD students and researchers to learn open-source investigation techniques and tools and not force them to learn R.
That’s enough content for one week. See you all next week, and looking forward to receiving any questions or comments at ari@glowstickintel.com!
Full circle moment, this may be my favorite blog post so far!